









PDF-Craft:PDF格式转换工具
简介
PDF craft 可以将 PDF 文件转化为各种其他格式。该项目将专注于扫描书籍的 PDF 文件的处理。
PDF craft可将 PDF 一页一页读出,并将书页中的正文提取出来,并过滤掉页眉、页脚、脚注、页码等元素。在跨页过程中,会使用算法判断以妥善处理前后文跨页顺接问题,最终生成语义通顺的文本。书页会使用 OnnxOCR 进行文本识别。并使用 layoutreader 来确定符合人类习惯的阅读顺序。
仅靠以上这些可在本地执行的 AI 模型(使用本地显卡设备来加速),便可将 PDF 文件转化为 Markdown 格式。这适应于论文或小书本。
但若要解析书籍(一般页数超过 100 页),建议将其转化为 EPUB 格式的文件。转化过程中,本库会将本地 OCR 识别出的数据传给 LLM,并通过特定信息(比如目录等)来构建书本的结构,最终生成带目录,分章节的 EPUB 文件。这个解析和构建的过程中,会通过 LLM 读取每页的注释和引用信息,然后在 EPUB 文件中以新的格式呈现。此外 LLM 还能在一定程度上矫正 OCR 的错误。这一步骤无法全在本地执行,你需要配置 LLM 服务,推荐使用 DeepSeek,本库的 Prompt 基于 V3 模型调试。
安装
你需要 python 3.10 或以上(推荐 3.10.16)。
pip install pdf-craftpip install onnxruntime==1.21.0使用 CUDA
如果你希望使用 GPU 加速,需要确保你的设备以准备好 CUDA 环境。请参考 PyTorch 的介绍,根据你的操作系统安装选择适当的命令安装。
此外,将前文安装 onnxruntime 的命令替换成如下:
pip install onnxruntime-gpu==1.21.0功能
PDF 转化为 MarkDown
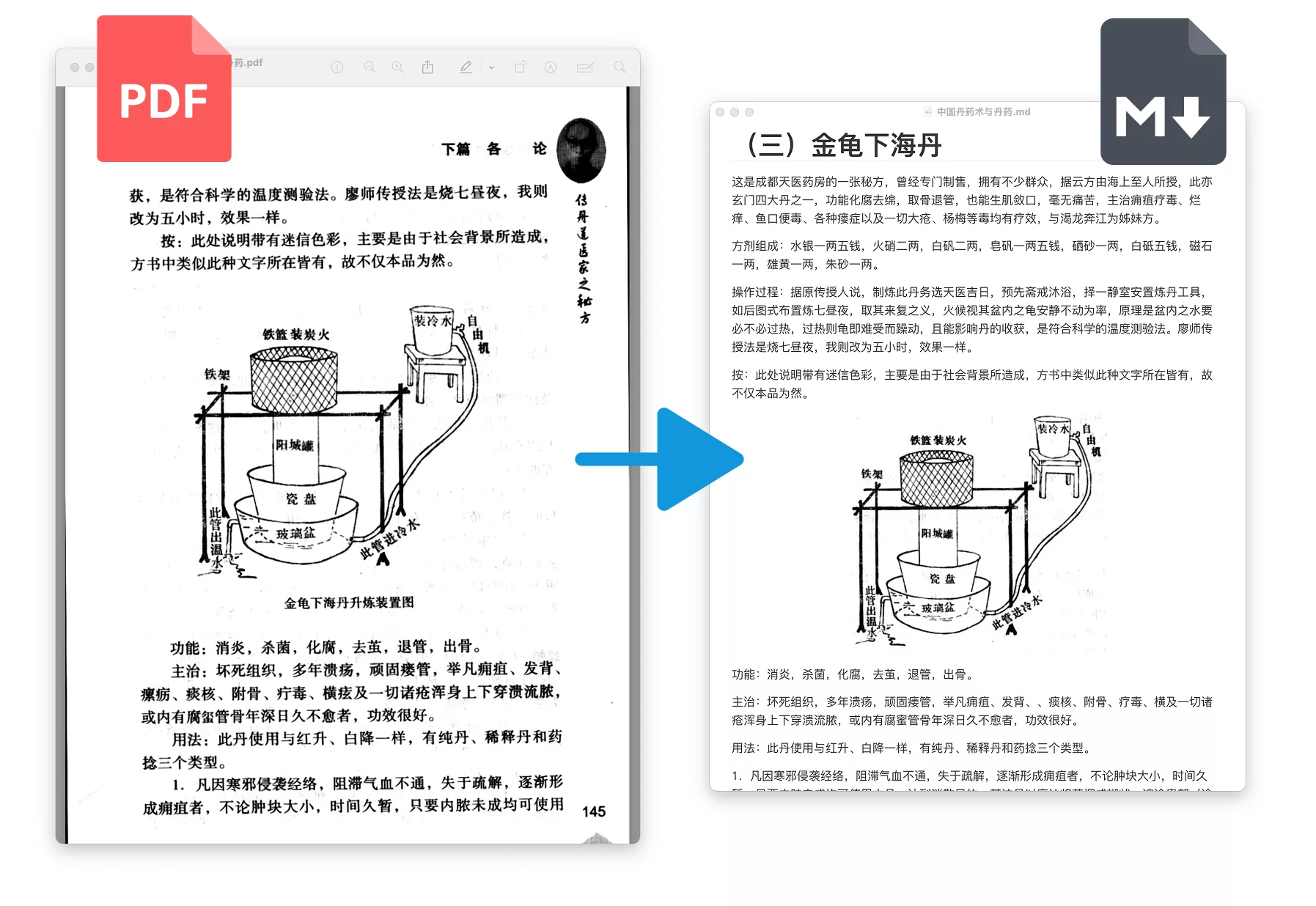
此操作无需调用远程的 LLM,仅凭本地算力(CPU 或显卡)就可完成。第一次调用时会联网下载所需的模型。遇到文档中的插图、表格、公式,会直接截图插入到 MarkDown 文件中。
from pdf_craft import PDFPageExtractor, MarkDownWriter
extractor = PDFPageExtractor(
device="cpu", # 如果希望使用 CUDA,请改为 device="cuda:0" 这样的格式。
model_dir_path="/path/to/model/dir/path", # AI 模型下载和安装的文件夹地址
)
with MarkDownWriter(markdown_path, "images", "utf-8") as md:
for block in extractor.extract(pdf="/path/to/pdf/file"):
md.write(block)执行完成后,会在指定的地址生成一个 *.md 文件。若原 PDF 中有插图(或表格、公式),则会在 *.md 同级创建一个 assets 文件夹,以保存图片。而 MarkDown 文件中将以相对地址的形式引用 assets 文件夹中的图片。
转化效果如下:
PDF 转化为 EPUB
此操作的前半部分与 PDF 转化 MarkDown(见前章节)相同,将使用 OCR 从 PDF 中扫描并识别文字。因此,也需要先构建 PDFPageExtractor对象。
from pdf_craft import PDFPageExtractor
extractor = PDFPageExtractor(
device="cpu", # 如果希望使用 CUDA,请改为 device="cuda:0" 这样的格式。
model_dir_path="/path/to/model/dir/path", # AI 模型下载和安装的文件夹地址
)之后,需要配置LLM对象。建议使用使用 DeepSeek,本库的 Prompt 基于 V3 模型调试。
from pdf_craft import LLM
llm = LLM(
key="sk-XXXXX", # LLM 供应商提供的 key
url="https://api.deepseek.com", # LLM 供应商提供的 URL
model="deepseek-chat", # LLM 供应商提供的模型
token_encoding="o200k_base", # 进行 tokens 估算的本地模型名(与 LLM 无关,若不关心就保留 "o200k_base")
)如上两个对象准备好后,就可以开始扫描并分析 PDF 书籍了。
from pdf_craft import analyse
analyse(
llm=llm, # 上一步准备好的 LLM 配置
pdf_page_extractor=pdf_page_extractor, # 上一部准备好的 PDFPageExtractor 对象
pdf_path="/path/to/pdf/file", # PDF 文件路径
analysing_dir_path="/path/to/analysing/dir", # analysing 文件夹地址
output_dir_path="/path/to/output/files", # 分析结果将写入这个文件夹
)上述代码注意两个文件夹地址,其一是 output_dir_path,表示扫描和分析的结果(会有多个文件)应该保存在哪个文件夹。该地址应该指向一个空文件夹,若不存在,则会自动创建一个文件夹。
其二是 analysing_dir_path,用来存储分析过程中的中间状态。在扫描和分析成功后,这个文件夹及其内部文件将变得没用(你可以用代码将它们删除)。该地址应该指向一个文件夹,若不存在,则会自动创建一个文件夹。这个文件夹(及其内部文件)可以保存分析进度。若某次分析因为意外而中断,可以通过将 analysing_dir_path 配置到上次被中断而产生的 analysing 文件夹,从而从上次被中断的点恢复并继续分析。特别的,如果你要开始一个全新的任务,请手动删除或清空 analysing_dir_path 文件夹,避免误触发中断恢复功能。
在分析结束后,将 output_dir_path 文件夹地址传给如下代码作为参数,即可最终生成 EPUB 文件。
from pdf_craft import generate_epub_file
generate_epub_file(
from_dir_path=output_dir_path, # 来自上一步分析所产生的文件夹
epub_file_path="/path/to/output/epub", # 生成的 EPUB 文件保存路径
)该步骤会根据之前分析的书本结构,在 EPUB 中分章节,并匹配恰当的目录结构。此外,原本书页底部的注释和引用将以合适的方式呈现在 EPUB 中。


功能进阶
多重 OCR
通过对同一页进行多次 OCR 来提高识别质量,避免字迹模糊而丢失文字的问题。
from pdf_craft import OCRLevel, PDFPageExtractor
extractor = PDFPageExtractor(
device="cpu",
model_dir_path="/path/to/model/dir/path",
ocr_level=OCRLevel.OncePerLayout,
)LLM 进阶
前文提及 LLM 的构建,可以为其添加更多的参数来实现更丰富的功能。以实现断线重连,或指定特定的超时时间。
llm = LLM(
key="sk-XXXXX",
url="https://api.deepseek.com",
model="deepseek-chat",
token_encoding="o200k_base",
temperature=0.3, # 温度(可选)
timeout=360, # 超时时间,单位秒(可选)
retry_times=10, # 因为网络原因或格式不完整请求失败所能接受的最大重试次数(可选)
retry_interval_seconds=6.0, # 重试之间间隔的时间,单位秒(可选)
)此外可将 temperature 设置成一个范围。在一般情况下,使用范围最左边的值作为温度。一旦 LLM 返回断裂的内容,则在重试时逐渐增加温度(不会超过范围右边的值)。以免 LLM 陷入总是返回断裂内容的循环之中。
llm = LLM(
key="sk-XXXXX",
url="https://api.deepseek.com",
model="deepseek-chat",
token_encoding="o200k_base",
temperature=(0.3, 1.0), # 温度(可选)
)